Permutation-Based Testing
Source:vignettes/permutation_based_testing.Rmd
permutation_based_testing.RmdBy default, CaDrA performs both forward and backward
search algorithm to look for a subset of features whose union is
maximally associated with an outcome of interest, based on (currently)
one of four scoring functions (Kolmogorov-Smirnov,
Conditional Mutual Information,
Wilcoxon, and custom-defined). To test
whether the strength of the association between the set of features and
the observed input scores (e.g., pathway activity, drug sensitivity,
etc.) is greater than it would be expected by chance,
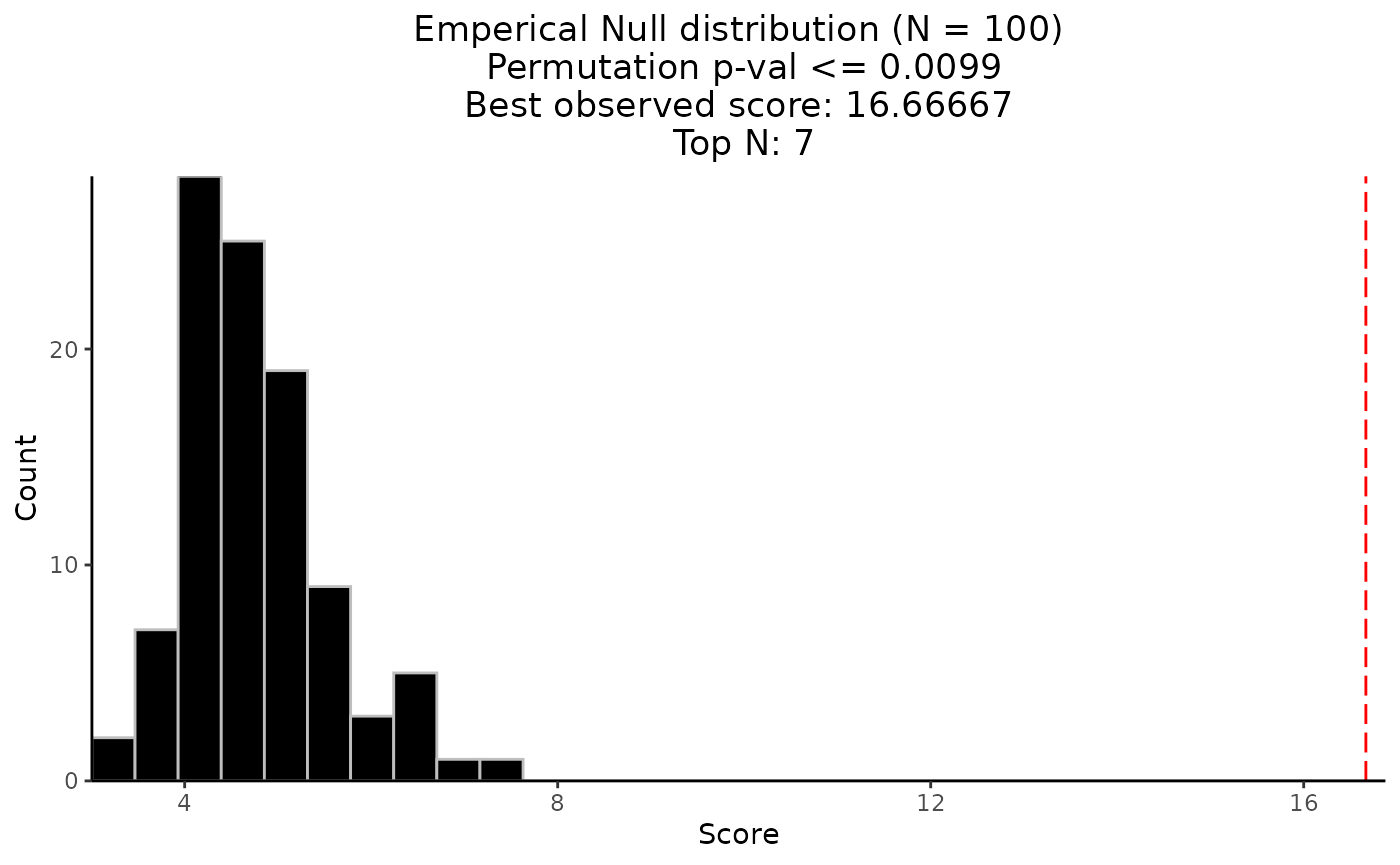
CaDrA supports permutation-based significance testing.
Importantly, the permutation test iterates over the entire search
procedure (e.g., if top_N = 7, each permutation iteration
will consist of running the search over the top 7 features).
Load required datasets
- A
binary features matrixalso known asFeature Set(such as somatic mutations, copy number alterations, chromosomal translocations, etc.) The 1/0 row vectors indicate the presence/absence of ‘omics’ features in the samples. TheFeature Setcan be a matrix or an object of class SummarizedExperiment from SummarizedExperiment package) - A vector of continuous scores (or
Input Scores) representing a functional response of interest (such as protein expression, pathway activity, etc.)
Find a subset of features that maximally associated with a given outcome of interest
Here we are using Kolmogorow-Smirnow (KS) scoring method to search for best features
candidate_search_res <- CaDrA::candidate_search(
FS = sim_FS,
input_score = sim_Scores,
method = "ks_pval", # Use Kolmogorow-Smirnow scoring function
method_alternative = "less", # Use one-sided hypothesis testing
weights = NULL, # If weights is provided, perform a weighted-KS test
search_method = "both", # Apply both forward and backward search
top_N = 7, # Number of top features to kick start the search
max_size = 10, # Allow at most 10 features in meta-feature matrix
best_score_only = FALSE # Return all results from the search
)Visualize best meta-features result
# Extract the best meta-feature result
topn_best_meta <- CaDrA::topn_best(topn_list = candidate_search_res)
# Visualize meta-feature result
CaDrA::meta_plot(topn_best_list = topn_best_meta)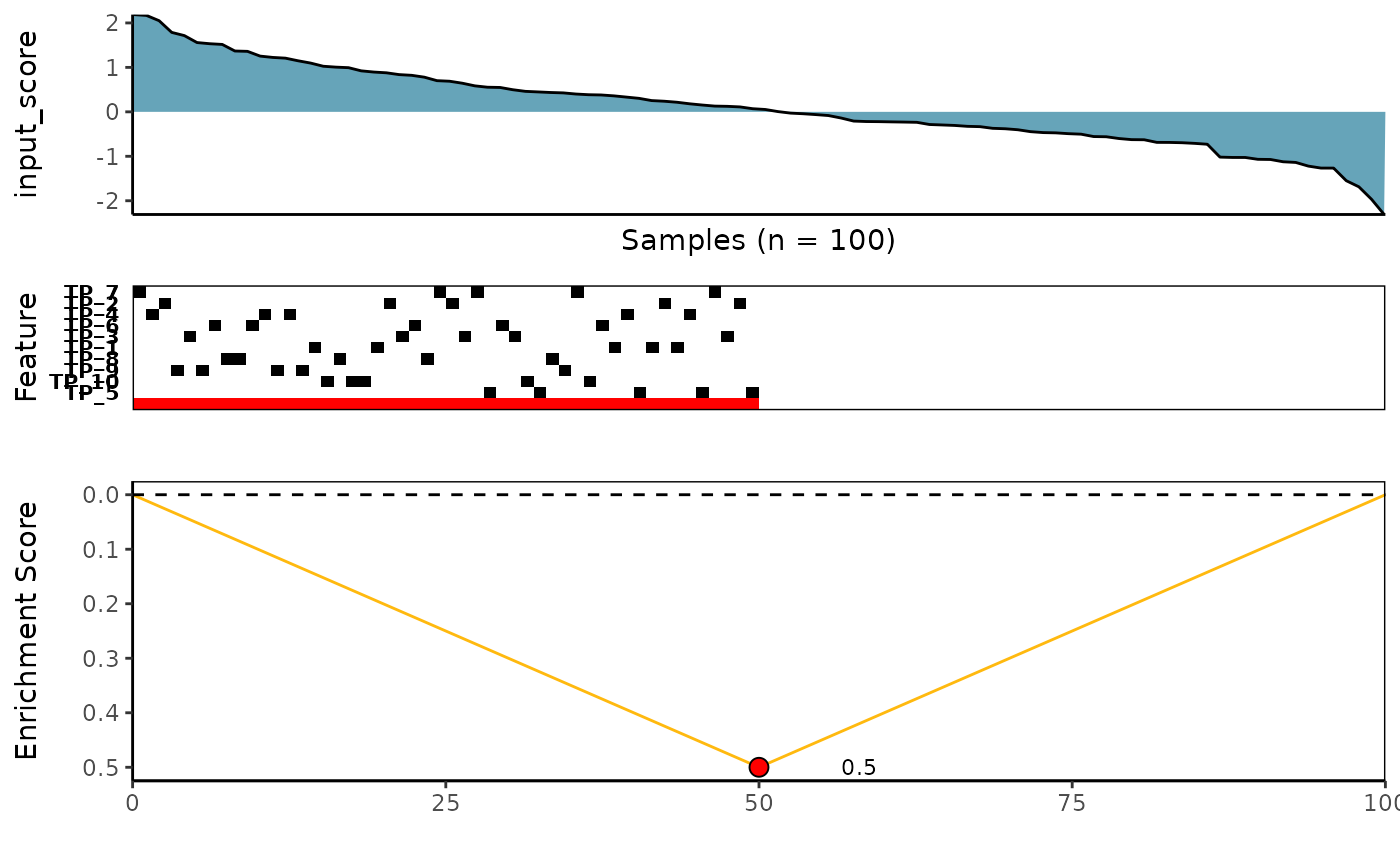
Perform permutation-based testing
# Set seed for permutation-based testing
set.seed(123)
perm_res <- CaDrA::CaDrA(
FS = sim_FS,
input_score = sim_Scores,
method = "ks_pval", # Use Kolmogorow-Smirnow scoring function
method_alternative = "less", # Use one-sided hypothesis testing
weights = NULL, # If weights is provided, perform a weighted-KS test
search_method = "both", # Apply both forward and backward search
top_N = 7, # Repeat the search with the top N features
max_size = 10, # Allow at most 10 features in the meta-feature matrix
n_perm = 100, # Number of permutations to perform
perm_alternative = "one.sided", # One-sided permutation-based p-value alternative type
plot = FALSE, # We will plot later
ncores = 2 # Number of cores to perform parallelization
)
SessionInfo
sessionInfo()
R version 4.5.1 (2025-06-13)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 24.04.3 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
locale:
[1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
[4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
[7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
time zone: UTC
tzcode source: system (glibc)
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] CaDrA_1.7.0 testthat_3.2.3 devtools_2.4.6 usethis_3.2.1
loaded via a namespace (and not attached):
[1] farver_2.1.2 R.utils_2.13.0
[3] S7_0.2.0 bitops_1.0-9
[5] fastmap_1.2.0 digest_0.6.37
[7] lifecycle_1.0.4 ellipsis_0.3.2
[9] processx_3.8.6 magrittr_2.0.4
[11] compiler_4.5.1 rlang_1.1.6
[13] sass_0.4.10 tools_4.5.1
[15] yaml_2.3.10 knitr_1.50
[17] labeling_0.4.3 S4Arrays_1.8.1
[19] htmlwidgets_1.6.4 pkgbuild_1.4.8
[21] DelayedArray_0.34.1 plyr_1.8.9
[23] RColorBrewer_1.1-3 abind_1.4-8
[25] pkgload_1.4.1 KernSmooth_2.23-26
[27] R.cache_0.17.0 withr_3.0.2
[29] purrr_1.1.0 BiocGenerics_0.54.0
[31] desc_1.4.3 R.oo_1.27.1
[33] grid_4.5.1 stats4_4.5.1
[35] caTools_1.18.3 ggplot2_4.0.0
[37] scales_1.4.0 gtools_3.9.5
[39] iterators_1.0.14 MASS_7.3-65
[41] SummarizedExperiment_1.38.1 cli_3.6.5
[43] crayon_1.5.3 ppcor_1.1
[45] rmarkdown_2.30 ragg_1.5.0
[47] generics_0.1.4 remotes_2.5.0
[49] rstudioapi_0.17.1 httr_1.4.7
[51] reshape2_1.4.4 sessioninfo_1.2.3
[53] cachem_1.1.0 stringr_1.5.2
[55] parallel_4.5.1 XVector_0.48.0
[57] matrixStats_1.5.0 vctrs_0.6.5
[59] Matrix_1.7-3 misc3d_0.9-1
[61] jsonlite_2.0.0 callr_3.7.6
[63] IRanges_2.42.0 S4Vectors_0.46.0
[65] systemfonts_1.3.1 foreach_1.5.2
[67] jquerylib_0.1.4 glue_1.8.0
[69] pkgdown_2.1.3 codetools_0.2-20
[71] ps_1.9.1 stringi_1.8.7
[73] gtable_0.3.6 GenomeInfoDb_1.44.3
[75] GenomicRanges_1.60.0 UCSC.utils_1.4.0
[77] knnmi_1.0 brio_1.1.5
[79] htmltools_0.5.8.1 gplots_3.2.0
[81] GenomeInfoDbData_1.2.14 R6_2.6.1
[83] tcltk_4.5.1 textshaping_1.0.4
[85] doParallel_1.0.17 rprojroot_2.1.1
[87] lattice_0.22-7 evaluate_1.0.5
[89] Biobase_2.68.0 R.methodsS3_1.8.2
[91] memoise_2.0.1 bslib_0.9.0
[93] Rcpp_1.1.0 SparseArray_1.8.1
[95] xfun_0.53 fs_1.6.6
[97] MatrixGenerics_1.20.0